linux 파일시스템 -1
📝 파일시스템이란?
- 파일시스템(File system)이란 파일(자료)를 사용자가 쉽게 접근 및 발견 할 수 있도록 운영체제가 시스템의 디스크상에 일정한 규칙을 가지고 보관하는 방식으로 리눅스 운영체제의 경우에는 파티션을 나누고 정리하는데 주로 사용됩니다. 운영체제가 파일들을 일정한 규칙을 연속적으로 사용하여 디스크의 파티션상에 저장하게 되면 저장장치 내에서 파일 저장을 저장하는게 용이해지고 파일을 검색,관리를 효율적으로 할 수 있습니다. 리눅스는 대표적으로 ext3, ext4 iso9660, swap, nfs, xfs등의 파일+시스템을 사용하고 있습니다.
2. 리눅스 전용 디스크 기반 파일 시스템 (EXT 시리즈)
| 파일 시스템 | 설명 |
|---|---|
| EXT | - 리눅스 초기에 사용되던 시스템 - 호환성 없음 - EXT2의 원형 - 2GB의 데이터와 파일명 255자까지 지정 가능 |
| EXT2 | - 고용량 디스크 사용을 염두하고 설계된 파일 시스템 - 호환과 업그레이드가 쉬움 - 4TB 파일 크기까지 지원 - 설정 방법) mke2fs - t ext2 |
| EXT3 | - 리눅스의 대표적인 저널링을 지원하도록 확장된 파일 시스템 - ACL (Access Control List)를 통한 접근 제어 지원 - 16TB의 파일 크기까지 지원 - 설정 방법 1) mke2fs -j - 설정 방법 2) mke2fs -t ext3 |
| EXT4 | - 파일에 디스크 할당 시 물리적으로 연속적인 블록을 할당 - 64비트 기억 공간 제한을 없앰 - 16TB 파일 크기까지 지원 - 설정 방법 1) mke2fs -t ext4 |
3. 저널링 파일 시스템 (JFS, XFS, ReiserFS, EXT3)
| 파일 시스템 | 설명 |
|---|---|
| JFS | - Journaling File System의 약자 - IBM사의 독자적인 저널링 파일 시스템 - GPL로 공개하여 현재 리눅스용으로 개발 |
| XFS | - eXetended File System의 약자 - 고성능 저널링 시스템 (SGI 제작) - 64bit 주소 지원 및 확장성 있는 자료 구조와 알고리즘 사용 - 데이터 읽기/쓰기 트랜잭션으로 성능 저하를 최소화 - 64bit 파일 시스템으로 8EB까지의 대용량 파일도 다룰 수 있음 |
| ReiserFS | - 독일의 한스 라이저가 개발한 파일 시스템 - 모든 파일 객체들을 B트리에 저장, 간결한 색인화된 디렉터리 지원 |
4. 네트워크 파일 시스템
| 파일 시스템 | 설명 |
|---|---|
| SMB | - Server Message Block - 옵션) smbfs - 삼바 파일 시스템을 마운트 지정 - 윈도우 계열 OS 환경에서 사용되는 파일/프린터 공유 프로토콜 - 리눅스, 유닉스 계절 OS와 윈도우 OS와의 자료 및 하드웨어 공유 (다른 OS와 자료 및 HW 공유 용이) |
| CIFS | - Common Internet File System - SMB를 확장한 파일 시스템 - SMB를 기초로 응용하여 라우터를 뛰어넘어 연결할 수 있는 프로토콜 |
| NFS | - Network File System - 옵션) nfs - 동일 OS간 RPC를 기반으로 파일 공유시 사용 권장 - 파일 공유 및 파일 서버로 사용하고, 공유된 영역을 마운트할 때 지정 - HW, OS 또는 네트워크 구조가 달라도 공유 가능 - NFS 서버의 특정 디렉터리를 마운트하여 사용 가능 |
| EXT4 | - 파일에 디스크 할당 시 물리적으로 연속적인 블록을 할당 - 64비트 기억 공간 제한을 없앰 - 16TB 파일 크기까지 지원 - 설정 방법 1) mke2fs-t ext4 |
5. 기타 파일 시스템
| 파일 시스템 | 설명 |
|---|---|
| FAT | - Windows NT가 지원하는 파일 시스템 중 가장 간단한 시스템 - 옵션) vfat - FAT로 포맷된 디스크는 클러스터 단위로 할당하며, 클러스터 크기는 볼륨 크기에 따라 결정 - 읽기 전용, 숨김, 시스템 및 보관 파일 특성만 지원 - 삼바 파일 시스템을 마운트 지정 |
| VFAT | - Virtual FAT - FAT 파일 시스템이 확장된 것으로 FAT보다 제한이 적음 - 파일 이름도 최고 255자까지 만들 수 있음 (= EXT) - 공백이나 여러 개의 구두점도 포함 |
| FAT32 | - SMB를 확장한 파일 시스템 - 다중 부팅 가능 - 파일 크기 최대 4GB, 파티션 크기 최대 32GB |
| NTFS | - 윈도우에서 사용하는 파일 시스템 - 옵션) ntfs - 안정성이 뛰어나고 대용량 파일도 저장 - 파일 크기 및 볼륨은 이론상 최대 16EB이지만, 실질적으로 2TB가 한계 |
| ISO 9660 | - CD-ROM의 표준 파일 시스템 - 옵션) loop - 1988년에 재정된 표준 |
| UDF | - Universal Disk Format의 약자로 최신 파일 시스템 형식 - 광학 매체용 파일 시스템 표준 - ISO 9660 파일 시스템을 대체하기 위한 것으로 대부분 DVD에서 사용 |
| HPFS | OS/2 운영체제를 위해 만들어진 파일 시스템 |
EXT 파일 시스템
EXT는 Linux의 가장 대표적인 파일 시스템입니다. Linux의 탄생에 많은 영향을 끼쳤던 초기 유닉스 계열 운영체제 중 하나인 MINIX에서 사용하던 파일 시스템에서 파일 이름과 파일 크기의 한계를 보완하며 설계되었습니다.


그러나 EXT는 data modification timestamp와 inode 수정을 지원하지 않으며, linked list를 통해 free block과 inode를 추적하기 때문에 성능이 저하된다는 문제점이 존재합니다. 이러한 EXT의 한계를 극복하기 위해 EXT2가 등장했습니다.
EXT2 파일 시스템
EXT2의 구조는 후속 EXT3, EXT4에서도 비슷한 구조로 이어지기에 보다 자세히 살펴보겠습니다.
디스크에서 파일 시스템은 파티션 당 하나씩 생성됩니다. 파티션에 EXT2를 구축하면 파티션은 다수의 블록 그룹(Block Group)으로 나뉩니다. 파일시스템을 블록 그룹으로 분할하면 같은 파일에 대한 inode와 data block이 인접한 실린더에 위치하게 되어 디스크 탐색시간(seek time)을 줄일 수 있다는 장점이 있습니다.
EXT2는 부트스트랩 코드가 존재하는 부트블록과 여러 개의 블록 그룹으로 구성됩니다. 그리고 블록 그룹은 다시 6가지 영역(super block, block group descriptor, block bitmap, inode bitmap, inode table, data blocks)으로 구분됩니다.
Super block
Super block은 파일시스템 구성에 대한 모든 정보를 포함합니다. Super block은 1024바이트 오프셋에 저장되며 파일시스템을 마운트 할 때 필수적으로 사용됩니다. Super block의 정보는 매우 중요하기 때문에 block group descriptor와 함께 모든 block group에 복사본이 존재합니다. 이 복사본이 너무 많은 저장 공간을 차지하는 대규모의 파일시스템의 경우 선택적으로 특정 그룹에만 backup을 보관하기도 합니다. EXT2의 super block 구조체는 다음과 같습니다.
ext2_super_block은 ‘fs/ext2/ext2.h’에 정의되어 있습니다.
struct ext2_super_block {
__le32 s_inodes_count; /* Inodes count */
__le32 s_blocks_count; /* Blocks count */
__le32 s_r_blocks_count; /* Reserved blocks count */
__le32 s_free_blocks_count; /* Free blocks count */
__le32 s_free_inodes_count; /* Free inodes count */
__le32 s_first_data_block; /* First Data Block */
__le32 s_log_block_size; /* Block size */
__le32 s_log_frag_size; /* Fragment size */
__le32 s_blocks_per_group; /* # Blocks per group */
__le32 s_frags_per_group; /* # Fragments per group */
__le32 s_inodes_per_group; /* # Inodes per group */
__le32 s_mtime; /* Mount time */
__le32 s_wtime; /* Write time */
...
}
Super block은 filesystem의 전체 inode와 block의 개수, free inode와 free block의 개수, block size, block group 당 inode 개수, filesystem mount 시간 등의 정보를 담고 있습니다.
Inode
ext2_inode는 ‘fs/ext2/ext2.h’에 정의되어 있습니다.
struct ext2_inode {
__le16 i_mode; /* File mode */
__le16 i_uid; /* Low 16 bits of Owner Uid */
__le32 i_size; /* Size in bytes */
__le32 i_atime; /* Access time */
__le32 i_ctime; /* Creation time */
__le32 i_mtime; /* Modification time */
__le32 i_dtime; /* Deletion Time */
__le16 i_gid; /* Low 16 bits of Group Id */
__le16 i_links_count; /* Links count */
__le32 i_blocks; /* Blocks count */
__le32 i_flags; /* File flags */
...
__le32 i_block[EXT2_N_BLOCKS]; /* Pointers to blocks */
...
};


아래는 i_mode field에 대한 설명입니다.
i_mode 필드는 16bit로 구성되며 상위 4bit는 파일의 유형을 의미합니다.
파일 유형


다음 3bits는 특수 권한으로 사용됩니다.
- u 비트는 setuid(set user id) 비트로 특정 작업 수행을 위해 일시적으로 파일 소유자의 권한을 얻는 데 사용됩니다.
- g 비트는 setgid(set group id) 비트로 일시적으로 파일 그룹의 권한을 얻게 됩니다.
- s 비트는 sticky 비트로 directory 파일에 sticky bit를 지정하면 누구나 파일을 생성할 수 있지만 자신의 소유가 아닌 파일은 삭제할 수 없습니다.
마지막 9bits는 파일의 접근 제어(읽기/쓰기/실행)에 사용됩니다. 3bits씩 user, group, 다른 사용자에 대한 접근 제어를 나타냅니다.
block bitmap/inode bitmap
inode table과 data blocks 내에서 빈 공간을 관리하기 위해 사용하며 각 bit는 각 inode/data block의 사용 여부를 나타냅니다. (사용 중인 경우 1, 빈 공간인 경우 0) 이 bitmap은 한 블록 내에 존재해야 하므로 블록의 크기가 4KiB인 경우 한 블록 그룹은 최대 4096*8개의 data block으로 구성될 수 있습니다.
inode table/data blocks
inode table과 data blocks 영역은 실제 inode 정보와 파일의 data 정보가 저장되는 공간입니다.
EXT2의 inode table과 data blocks의 구조를 더 자세히 살펴보겠습니다.
위 그림은 /(root directory) 아래에 file1.c 파일과 mydir 디렉터리가 존재하고, mydir 디렉터리 아래에 file2.c가 존재하는 경우 EXT2의 구조를 나타냅니다. EXT2의 root directory는 항상 inode 2번을 사용하며 inode 10번까지는 미리 예약되어 있기 때문에 사용자가 생성한 파일의 경우 inode 11번부터 할당됩니다.
이때 ‘/mydir/file2.c’ 파일을 찾아가는 과정을 살펴보겠습니다.
- 먼저 /(root directory)를 찾기 위해 inode table에서 2번 inode를 검색합니다. inode의 i_block field를 통해 해당 파일의 data block number를 찾을 수 있습니다.
- root directory의 i_block field의 값은 20이므로 20번 data block에 root directory가 존재합니다. root directory는 디렉터리 파일이므로 data block에 directory entry가 존재합니다.
- directory entry는 해당 디렉터리에 존재하는 파일들의 inode 번호와 파일 이름을 가지고 있습니다. root directory의 data block을 확인하면 file1.c와 mydir가 존재하며 각각 11번과 12번 inode에 해당하는 것을 볼 수 있습니다.
- 이제 mydir의 inode인 12번 inode를 확인하면 mydir가 24번 data block에 저장된 것을 알 수 있습니다. data block 24번에서 file2.c의 inode 번호(13)를 알아내고 13번 inode의 i_block field를 통해 file2.c가 25,26,27번 data block에 저장된 것을 확인할 수 있습니다.
이러한 과정을 거쳐 file2.c의 data를 검색할 수 있습니다.
EXT2의 가장 큰 단점은 디스크에 data를 쓰는 동안 시스템 충돌이 발생하거나 전원이 끊어지면 심각한 손상을 입는다는 것입니다. 이때 재부팅이 이루어지는데, e2fsck라는 검사 프로그램을 전체 파일시스템을 대상으로 실행해야 하며 검사 중에는 파일시스템을 사용할 수 없습니다. 이러한 EXT2의 한계를 극복하고 기능을 보완하는 EXT3가 등장했습니다.
EXT3 파일시스템
EXT2과 비교해 EXT3에 새로 추가된 기능을 중심으로 알아보겠습니다.
1) HTree 기술 도입
EXT3에는 directory 검색 성능을 높이기 위해 hash 기반 HTree 기술이 도입되었습니다.
EXT2는 directory를 단순 연결 리스트로 관리합니다. 따라서 directory 내의 파일 수가 증가하는 경우 파일 검색 시간 또한 선형적으로 증가하게 됩니다. 이러한 문제를 해결하기 위해 EXT3는 HTree 구조를 도입하여 directory 내에 많은 파일이 존재하더라도 상수 시간 안에 접근할 수 있도록 했습니다.
+ HTree란?
B-Tree와 유사하며 directory indexing을 위한 특수 트리 데이터 구조입니다. filename의 hash를 사용하며 tree는 단일 directory entry를 가리키는 것이 아니라 directory entry들이 저장되어 있는 block을 가리킵니다. HTree는 최대 2 level이므로 검색은 상수 시간 안에 가능합니다. Hash 값의 마지막 1bit는 hash collision을 나타냅니다. Hash collision chain의 마지막 block을 제외하고 모든 block은 collision bit가 set 되어 있습니다. 따라서 collision bit가 1인 경우 다음 block을 이어서 검사합니다. HTree는 EXT3, EXT4에서 사용되며 약 Linux Kernel v2.5부터 커널에 통합되었습니다.
2) 저널링(journaling) 기능 지원
저널링이란 시스템 충돌이나 정전과 같은 이벤트로 인해 발생할 수 있는 파일시스템 손상을 신속하게 복구하는 기능으로 EXT3에 추가된 주요 기능 중 하나입니다.
앞서 설명하였 듯 EXT2에서 충돌이 발생하면 파일시스템 전체를 스캔합니다. 재부팅 시에 e2fsck(filesystem consistency check) 를 실행하여 모든 항목을 검증하고 블록이 올바르게 할당되고 참조 되는지 확인해야 합니다. 그러나 대용량 파일시스템은 e2fsck 프로세스를 완료하는데 매우 오랜 시간이 소요되며 이 시간 동안 파일시스템을 사용할 수 없다는 문제가 발생합니다.
이에 반해 EXT3는 전체 파일시스템을 검사할 필요가 없습니다. EXT3는 데이터를 파일시스템의 실제 영역에 기록하기 전에 해당 정보를 log 영역에 기록합니다. log 영역에 기록하는 정보의 양은 아무것도 기록하지 않거나 메타데이터만 기록하거나, 메타데이터와 데이터 블록을 함께 기록하는 등 설정이 가능합니다. 이처럼 log를 기록하면 시스템이 갑자기 종료되더라도 그 위치를 파악할 수 있고 파일시스템 전체를 검사할 필요가 없어집니다.
EXT3에는 3가지 저널링 모드가 존재합니다.


그러나 EXT3는 파일시스템과 파일의 최대 크기가 작고 연속적인 데이터 블록에 대해 비효율적인 인덱싱 방식을 사용하는 등 여러 단점이 존재합니다. 이러한 EXT3의 여러 단점을 보완하고 한계를 극복한 EXT4가 등장했습니다.
EXT4 파일시스템
EXT3와 비교하여 EXT4에 추가된 기능들을 중심으로 살펴보겠습니다.
1) 대용량 파일시스템과 파일 크기 지원

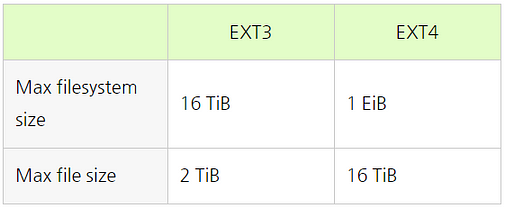
(4KiB block size 기준)
EXT4는 48bits 블록 주소 지정을 사용하기 때문에 EXT3보다 더 큰 파일 시스템과 파일 크기를 지원할 수 있습니다.
2) Pre-allocation(사전 할당)
파일 생성 시 미리 일정 개수의 블록을 보장하는 기법입니다. EXT4에서는 fallocate() 시스템 콜을 이용하여 pre-allocation 기능을 제공합니다.
EXT3는 파일에 대한 disk 공간을 할당할 때 해당 블록에 0을 write 해야 했지만 EXT4에서는 pre-allocation 하여 효율적인 블록할당이 가능합니다. 또한 블록을 연속적으로 미리 할당하여 fragmentation이 개선되는 효과를 보입니다. 프로세스가 필요한 공간을 확보하도록 보장하기에 중요한 작업 중간에 저장 공간이 부족한 일을 방지할 수도 있습니다.
3) Delayed allocation(지연 할당)
free block count만 갱신하고 실제 블록 할당은 뒤로 미루는 방식입니다.
EXT3는 프로세스가 write()를 실행한 경우 데이터를 저장할 블록을 즉시 할당합니다. 따라서 연속적으로 write()를 실행하여 파일의 크기가 계속 증가하더라도 그때마다 블록을 추가적으로 할당합니다.
EXT4는 프로세스가 write() 했을 때 블록을 즉시 할당하지 않고 데이터가 실제 disk에 write 될 때까지(파일이 cache에 보관되어 있는 경우) 할당을 지연합니다. 따라서 block allocator가 블록 할당을 최적화할 수 있기 때문에 성능이 향상되고 fragmentation을 개선할 수 있습니다.
4) Extent
대용량 파일의 메타데이터를 줄이고 성능을 향상시키기 위한 기법입니다.
EXT2, EXT3의 경우에는 inode의 direct/indirect block을 통해 파일의 데이터 블록에 접근합니다. 이때 disk 상에 연속적으로 블록을 할당하더라도 모든 단일 블록에 대한 매핑을 유지해야 합니다.
EXT4에서는 이러한 문제를 해결하기 위해 extent를 사용합니다. 예를 들어 100번 블록부터 연속적인 50개 블록을 할당한 경우 (100, 50)과 같은 정보만을 유지하여 메타데이터의 양을 줄이고 데이터 블록을 인덱싱하는 시간을 줄일 수 있습니다. 4KiB block size를 갖는 파일시스템의 단일 extent는 최대 128MiB의 연속 공간을 매핑할 수 있습니다.
Linux의 EXT4 코드를 보며 extent가 실제로 어떻게 구현되어 있는지 살펴보겠습니다.
ext4_inode는 ‘fs/ext4/ext4.h’에 정의되어 있습니다.
#define EXT4_NDIR_BLOCKS 12
#define EXT4_IND_BLOCK EXT4_NDIR_BLOCKS
#define EXT4_DIND_BLOCK (EXT4_IND_BLOCK + 1)
#define EXT4_TIND_BLOCK (EXT4_DIND_BLOCK + 1)
#define EXT4_N_BLOCKS (EXT4_TIND_BLOCK + 1)struct ext4_inode {
__le16 i_mode; /* File mode */
__le16 i_uid; /* Low 16 bits of Owner Uid */
__le32 i_size_lo; /* Size in bytes */
__le32 i_atime; /* Access time */
__le32 i_ctime; /* Inode Change time */
__le32 i_mtime; /* Modification time */
__le32 i_dtime; /* Deletion Time */
__le16 i_gid; /* Low 16 bits of Group Id */
__le16 i_links_count; /* Links count */
__le32 i_blocks_lo; /* Blocks count */
... /* OS dependent 1 */
__le32 i_block[EXT4_N_BLOCKS];/* Pointers to blocks */
...
}
EXT2와 마찬가지로 data block을 가리키기 위해 inode의 i_block field를 이용합니다. 이때, EXT4_N_BLOCKS == 15이므로 i_block의 size는 15 * 4 = 60bytes가 됩니다. extent의 경우 60bytes를 아래와 같은 format으로 사용합니다.
위 그림처럼 하나의 inode에는 최대 4개의 extent가 직접 연결될 수 있습니다. 5개 이상의 extent가 필요한 대용량 파일의 경우에는 HTree 방식의 extent tree가 사용됩니다. 다음은 EXT4의 extent tree 구조입니다.
그림 출처: https://www.kernel.org/doc/ols/2007/ols2007v2-pages-21-34.pdf
index node는 다음 level의 index node 또는 leaf node를 가리키며 leaf node는 데이터가 저장되어 있는 data block을 가리킵니다.
각 node의 실제 코드를 통해 더 자세히 알아보겠습니다.
ext4_extent, ext4_extent_idx, ext4_extent_header는 ‘fs/ext4/ext4_extents.h’에 정의되어 있습니다.
/*
* This is the extent on-disk structure.
* It's used at the bottom of the tree.
*/
struct ext4_extent {
__le32 ee_block; /* first logical block extent covers */
__le16 ee_len; /* number of blocks covered by extent */
__le16 ee_start_hi; /* high 16 bits of physical block */
__le32 ee_start_lo; /* low 32 bits of physical block */
};
/*
* This is index on-disk structure.
* It's used at all the levels except the bottom.
*/
struct ext4_extent_idx {
__le32 ei_block; /* index covers logical blocks from 'block' */
__le32 ei_leaf_lo; /* pointer to the physical block of the next *
* level. leaf or next index could be there */
__le16 ei_leaf_hi; /* high 16 bits of physical block */
__u16 ei_unused;
};
/*
* Each block (leaves and indexes), even inode-stored has header.
*/
struct ext4_extent_header {
__le16 eh_magic; /* probably will support different formats */
__le16 eh_entries; /* number of valid entries */
__le16 eh_max; /* capacity of store in entries */
__le16 eh_depth; /* has tree real underlying blocks? */
__le32 eh_generation; /* generation of the tree */
};
- struct ext4_extent의 ee_len field는 연속된 block의 개수를 나타냅니다. ee_len field는 __le16 type이고 MSB(most significant bit)는 사전 할당에서 초기화되지 않은 extent를 나타내는 flag로 사용됩니다. 따라서 최대 2¹⁵개의 연속 블록을 나타낼 수 있고 block size가 4KiB인 경우 최대 4KiB * 2¹⁵ = 128MiB의 연속 블록을 나타낼 수 있습니다.
- ee_start_hi와 ee_start_lo는 각각 data block의 상위 16bit, 하위 32bit를 나타냅니다. (위에서 언급했듯이 EXT4에서는 48bit 블록 주소 지정을 사용한다는 사실을 기억해 주세요.)
- ee_block field는 logical block number(해당 파일 내에서의 block number)를 의미하고 ee_start_hi, ee_start_lo field는 physical block number(전체 data block에서의 block number)를 의미합니다.
이처럼 EXT4는 extent를 이용하여 파일의 data block에 접근합니다. extent는 연속적으로 할당된 블록에 대해 단일 블록을 매핑할 필요가 없기 때문에 대용량 파일의 메타데이터를 줄일 수 있습니다. 또한 disk에서 연속적인 레이아웃을 장려하기 때문에 fragmentation을 감소시키는 데에도 도움이 됩니다.
XFS
XFS는 1993년 Silicon Graphics에서 개발한 고성능의 64bit 저널링 파일시스템입니다. 이후 2001년에 리눅스 커널에 포함되었으며 오늘날 대부분의 리눅스 배포판에서 지원되고 있습니다. 대용량 디스크의 사용이 보편화되고 더 큰 파일 크기 및 파일시스템의 크기가 요구되면서 RHEL7(Red Hat Enterprise Linux 7)에 이어 Oracle Linux 7, CentOS 7 등 여러 배포판에서 EXT4 대신에 XFS를 기본 파일시스템으로 채택하였습니다.
XFS의 특징을 나열하면 아래와 같습니다
✔ 64bit 파일시스템으로 대용량 파일시스템에 효율적입니다.
✔ EXT4보다 큰 최대 16 EiB 파일시스템과 최대 8EiB 파일을 지원할 수 있습니다.
✔ B+tree를 사용하여 우수한 I/O 확장성을 제공하고 모든 사용자 데이터 및 메타데이터를 인덱싱합니다.
✔ 파일시스템이 마운트 되어 활성화되어 있는 동안 확장이 가능합니다.
✔ 파일시스템의 크기는 줄일 수는 없습니다.
✔ extent 기반 할당을 사용하며 지연할당 및 사전 할당과 같은 여러 할당 체계를 가지고 있습니다.
✔ extent 기반 할당은 메타데이터의 양을 감소시키고 단편화를 줄임으로써 대용량 파일의 성능을 향상시킵니다.
✔ 지연할당을 통해 파일이 연속적인 블록 그룹에 저장될 가능성을 높이기 때문에 단편화를 줄이고 성능을 향상시킵니다.
✔ 사전 할당을 통해 애플리케이션이 사전에 저장할 데이터의 양을 알고 있는 경우 조각화를 방지하는 데 사용될 수 있습니다.
XFS는 data section, log section, real-time section 등으로 구성됩니다. 기본 mkfs.xfs 옵션을 사용하면 real-time section이 없으며 log section이 data section 내에 포함됩니다. log section은 data section 내에 포함될 수도 있고 분리될 수도 있습니다. 파일시스템 section은 특정 수의 block으로 나뉘며 크기는 mkfs.xfs 명령의 -b 옵션으로 지정됩니다.
data section은 여러 allocation group(AG)으로 나누어지며 각 AG는 일반적으로 동일한 크기를 가집니다. XFS의 AG는 EXT 계열의 block group과 유사하지만 일반적으로 block group보다 크고 디스크 인접성보다는 확장성과 병렬성을 위해 사용됩니다.
AG의 수는 파일 및 블록 할당에서 사용 가능한 병렬 처리량을 제어합니다. 메모리가 충분하고 할당 작업이 많은 경우에는 AG의 수를 기본값보다 증가시켜야 합니다. 더 많은 AG를 추가하기 위해서는 xfs_growfs 를 실행합니다.
Allocation group(AG)의 구조에 대해서 살펴보겠습니다.
그림 출처: http://www.dubeyko.com/development/FileSystems/XFS/xfs_filesystem_structure.pdf
각 AG의 첫 번째 sector는 super block을 나타냅니다. 첫 번째 super block은 primary super block입니다. 이후에는 primary super block의 복사본일 뿐이며 primary super block이 손상된 경우에만 xfs_repair에 사용됩니다.
EXT 계열에서는 선형 bitmap을 이용하여 free space를 추적합니다. 그러나 이는 대용량 연속 할당의 경우 특히 비효율적입니다. 따라서 XFS는 각 AG마다 B+tree를 이용하여 free space를 관리합니다.
B+tree의 각 노드는 free space의 시작 block과 block count로 구성됩니다. 첫 번째 B+tree는 free space의 시작 block을 기준으로 인덱싱되고 두 번째 B+tree는 free space의 block count를 기준으로 인덱싱됩니다. 이렇게 이중 인덱싱을 이용하면 기존 파일 데이터에 대한 인접성과 free space의 best fit 두 가지 목표를 고려하여 free space를 할당할 수 있습니다.
AG의 두 번째 sector는 두 개의 free space B+tree와 free space 관련 정보를 나타냅니다. 실제 코드를 통해 더 자세히 살펴보겠습니다.
xfs_agf는 ‘fs/xfs/libxfs/xfs_format.h’에 정의되어 있습니다.
typedef struct xfs_agf {
...
__be32 agf_roots[XFS_BTNUM_AGF]; /* root blocks */
__be32 agf_levels[XFS_BTNUM_AGF]; /* btree levels */
...
} xfs_agf_t;
XFS_BTNUM_AGF는 3으로 set 되어 있습니다. agf_roots와 agf_levels의 index가 0인 경우 block number로 인덱싱되는 B+tree를 나타내고 index가 1인 경우 block count로 인덱싱되는 B+tree를 나타내고 index가 2인 경우 역방향 매핑 B+tree를 나타냅니다.
agf_roots field는 각 B+tree의 root block number를 지정합니다. agf_levels field는 각 B+tree의 level 또는 depth를 지정합니다. 새로운 AG의 경우 이 값은 1이 될 것이며 agf_roots는 level 0의 단일 leaf를 가리킬 것입니다.
free space B+tree 구조를 그림으로 나타내면 다음과 같습니다.
그림 출처: http://www.dubeyko.com/development/FileSystems/XFS/xfs_filesystem_structure.pdf
위 구조는 하나의 leaf 노드를 가지는 단일 level B+tree의 구조입니다. agf_roots[0]은 시작 block number를 기준으로 하는 B+tree를 나타내고 agf_roots[1]은 block count를 기준으로 하는 B+tree를 나타내는 것을 볼 수 있습니다.
AG의 세 번째 sector는 AG의 inode에 관한 정보를 가지고 있습니다. XFS의 inode는 동적으로 할당되며 다른 linux 파일시스템과 달리 inode의 위치와 숫자가 mkfs time에 결정되지 않습니다. 따라서 inode의 위치와 할당을 추적하기 위해 추가적인 데이터 구조가 필요하며 이를 위해 B+tree를 이용합니다.
즉 XFS는 64bit 파일시스템으로 대용량 파일시스템에 적합하며 B+Tree를 이용하여 우수한 확장성을 제공하고 xfs_growfs 를 통해 마운트 된 상태에서도 파일시스템 확장이 가능하다는 장점이 있으나, 작은 사이즈의 파일에서는 실행이 느리며 파일시스템 축소는 불가능하다는 단점이 존재한다고 요약할 수 있겠습니다.
Btrfs
Btrfs는 ‘B-tree filesystem’ 또는 ‘Butter filesystem’의 약자로 Copy-on-Write 파일시스템입니다. 2013년에 linux kernel에 포함되었으며 SUSE Linux Enterprise 12의 기본 파일시스템으로 사용됩니다.
EXT4와 Btrfs는 서로 다른 유형의 문제를 해결하도록 설계되었습니다. 두 파일 시스템을 유사점과 차이점을 중심으로 비교해보겠습니다.
1) 파일시스템과 파일 최대 크기


2) Inode 할당 방식
inode는 파일 또는 디렉터리 당 하나씩 존재합니다. EXT4의 경우에는 파일시스템을 생성하면서 파일시스템이 지원하는 최대 inode의 개수를 정의합니다. 따라서 파일시스템이 생성된 후에는 지원 가능한 최대 inode 개수를 변경할 수 없습니다. EXT4에서는 작은 크기의 파일을 많이 생성하는 경우 파일시스템에 free space가 남아있더라도 free inode가 부족하여 파일을 생성하지 못할 수도 있습니다.
그러나 Btrfs는 유연한 inode 할당 방식을 가지고 있으므로 필요한 만큼 inode의 개수를 추가할 수 있습니다. 따라서 inode가 부족하여 파일을 생성하지 못하는 문제는 발생하지 않습니다.
3) Journaling & Copy-on-Wirte
EXT4는 journaling 파일시스템이지만 Copy-on-Write는 지원하지 않습니다. 반대로 Btrfs는 Copy-on-Write 파일시스템이지만 journaling을 지원하지 않습니다.
Btrfs는 블록의 변경 사항을 journaling 하는 대신 새로운 위치에 기록한 다음 link를 변경합니다. write가 끝나기 전까지 변경사항은 commit되지 않습니다. 기존 데이터가 수정되지 않으므로 write 도중 시스템 충돌이나 정전이 발생하더라도 기존 데이터는 손상되지 않습니다.
4) Filesystem snapshot
EXT4는 파일시스템의 snapshot을 지원하지 않습니다. 그러나 Btrfs는 파일시스템 snapshot을 지원합니다.
파일시스템의 snapshot 기능을 이용하면 위험한 작업을 수행하기 전에 파일시스템의 snapshot을 저장할 수 있습니다. 일이 계획대로 진행되지 않는다면 작업 수행 전의 상태로 되돌릴 수 있습니다. 이는 Btrfs의 내장 기능으로 다른 tool이나 소프트웨어를 사용할 필요가 없습니다.
5) Extent
EXT4와 Btrfs는 모두 extent 기반의 파일시스템입니다.
6) Block size
EXT4는 고정 블록 크기를 지원합니다. 블록 크기는 파일시스템이 생성되기 전에 결정됩니다. 따라서 파일시스템 생성 후에는 블록 크기를 변경할 수 없습니다. 반대로 Btrfs는 가변 블록 크기를 지원합니다. 따라서 파일 크기에 따라 가장 적합한 블록 크기를 결정할 수 있습니다. 이 기능을 이용하면 디스크 공간을 절약할 수 있습니다.
EXT4는 오랜 기간 동안 linux에서 사용되어 왔으며 여러 리눅스 배포판(Ubuntu, Debian 등)에서 기본 파일시스템으로 사용됩니다. 또한 Btrfs와는 달리 linux뿐만 아니라 FreeBSD도 지원합니다. EXT4는 Btrfs에 비해 속도가 빠르고 안정적이라는 장점이 있습니다.
반대로 Btrfs는 파일시스템 snapshot 기능을 내장하고 있으며 유연한 inode 할당 방식, 가변 블록 크기를 지원하는 등의 장점이 있습니다.
ZFS
ZFS는 Sun Microsystems에서 개발한 파일시스템으로 Solaris에 탑재되었습니다. ZFS는 128bit 파일시스템으로 64bit 파일시스템보다 1.84*10¹⁹배의 데이터를 처리할 수 있습니다. 또한 Btrfs와 마찬가지로 Copy-on-Write를 지원하여 파일을 수정할 때 기존 데이터를 새로운 데이터로 덮어쓰지 않습니다. 이외에도 ZFS의 몇 가지 특징에 대해 더 살펴보겠습니다.
1) Data Integrity
ZFS는 정전, 시스템 충돌 등으로부터 사용자의 데이터를 보호함으로써 데이터 무결성에 중점을 두고 설계되었습니다.
ZFS에서 데이터 무결성은 Fletcher-based checksum 또는 SHA-256를 사용하여 달성됩니다. 블록에 access 하면 데이터인지 메타데이터인지에 관계없이 checksum이 계산되고 저장된 checksum과 비교합니다. checksum이 일치하면 해당 데이터를 요청한 프로세스에게 전달합니다. 그러나 checksum이 일치하지 않는다면 데이터 중복을 제공하는 경우 중복 데이터가 손상되지 않고 checksum이 일치한다고 가정하고 데이터를 복구할 수 있습니다.
2) Mirror & RAID-Z
ZFS는 하드웨어 RAID 대신에 disk mirroring과 RAID-Z라는 기능을 제공합니다.
때문에 하드웨어 디바이스를 통해 RAID를 수행하는 경우 운영체제와 파일시스템은 RAID 메커니즘을 인식하지 못합니다. 전용 하드웨어인 RAID card 자체에서 오류가 발생하는 경우 전체 디스크 array가 무용지물이 되는 경우도 있습니다. 이를 방지하기 위해서는 하드웨어 RAID controller가 없는 ZFS를 사용해야 합니다.
Disk mirroring은 데이터를 별도의 디스크에 복사하여 저장하는 방식으로 디스크 장애 발생 시 복사본을 이용하여 데이터를 복구합니다.
RAID-Z는 RAID-Z1라고도 불리며 최소 3개 이상의 디스크로 분리하여 데이터 손상을 방지합니다. 3개의 디스크를 이용하는 경우를 예로 들어 보겠습니다. 3개의 디스크를 virtual device(vdev)로 결합합니다. 1GB 크기의 파일을 pool에 저장한다고 가정하면 RAID-Z는 파일을 512MB의 두 개의 덩어리로 분할합니다. 그리고 수학적 연산을 수행하여 parity block이라 불리는 512MB 크기의 세 번째 덩어리를 생성합니다. 그리고 이 세 덩어리를 세 개의 분리된 vdev에 기록합니다. 이제 세 개의 디스크 중 하나에 장애가 발생하면 나머지 두 디스크를 이용하여 손상된 데이터를 복구할 수 있습니다. 실제 파일의 크기보다 50% 이상의 저장 공간을 더 필요로 하지만 vdev 별 단일 디스크 장애로부터 안전하다는 장점이 있습니다.
그러나 RAID-Z1은 두 개 이상의 디스크 장애는 복구할 수 없습니다. 이를 극복하기 위해서는 RAID-Z2를 이용해야 합니다. RAID-Z2는 단일 정보에 대해 2개의 data block과 2개의 parity block을 생성합니다. 따라서 vdev 당 최대 2개의 디스크 장애로부터 안전합니다. 또한 RAID-Z2 설정을 구현하려면 vdev 당 최소 4개의 디스크가 요구됩니다.
마찬가지로 RAID-Z3는 vdev 당 최소 5개의 디스크가 필요하며 3개의 디스크 장애까지 데이터 복구가 가능합니다. disk mirroring은 RAID 1과 유사하고, RAID-Z1은 RAID 5와 유사하고, RAID-Z2는 RAID 6와 유사하고, RAID-Z3는 RAID 7과 유사합니다.
지금까지 다양한 linux 파일시스템의 종류와 그 특징에 대해 알아보았습니다. 각 파일시스템의 동작은 서로 다르며 그에 따라 호출해야 하는 함수도 달라질 것입니다.
- 그렇다면 사용자 애플리케이션은 어떻게 디바이스의 파일시스템을 판별하고 그에 해당하는 함수를 호출하는 걸까요?
- 파일시스템의 종류에 관계없이 일관된 함수를 통해 파일시스템에 접근할 수는 없는 걸까요?
이것은 linux의 VFS(Virtual FileSystem)을 통해 가능합니다. 다음 장에서는 이러한 VFS에 대해 더 자세히 살펴보겠습니다.
댓글남기기